一.Explain是什么
explain是mysql里面用于分析sql语句在执行计划的,如下图,使用方法就是在sql语句之前加上这个关键字,然后通过下面的信息来分析这个sql语句。

二.字段详解
1.id:select查询的序列号,如果id全部相同,则执行顺序由上到下。如果id全部不同,递增,id越大,先被执行查询。如果id相同不同都有,那么id相同的一组顺序执行,所有组中id越大越先被执行。
2.select_type:查询的类型,有六种,不太有用的东西,可忽略。
3.type:访问类型,System(只有一条记录)到Const(索引一次找到)到eq_ref(每个索引只有一个记录)到ref(返回匹配的所有行)到range(使用索引选择行)到all,一般来说,能保证sql语句到range,ref更好,已经可以了。
4.possible_key:显示可能用到的索引。
5.key:实际使用到的索引。
6.key_len:索引长度。
7.ref:显示索引的那一列被使用了。
8.rows:系统估计读取的行数
9.extra:
using filesort:说明你设的索引系统没有用,它又自己进行文件内排序,出现这个情况十分糟糕。
using temporary:说明产生了临时表,一般都是order by和分组group by的时候,这个情况非常非常糟糕。
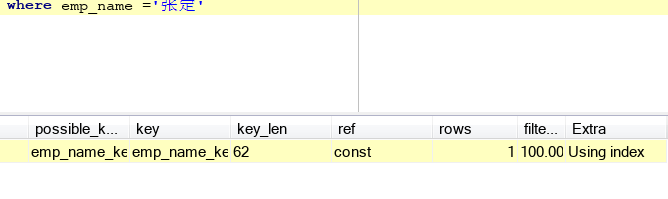
using index :很好,这个情况最好,表面使用了覆盖索引,看下图,emp_name为索引,这样使用到了索引。
三.SQL语句优化
1.大体流程
a.首先,先跑一天sql,开启慢查询日志,设置阙值。
b.然后,使用explain分析慢查询 的那些sql
c.到这里其实基本解决了80%的问题,如果还想搞,可以使用show profile看看sql在mysql里面的执行细节以及生命周期。
2.常见的查询优化
a.联合查询时,小表驱动大表,所以要先查小表(连接数少,一次查询的数目多)
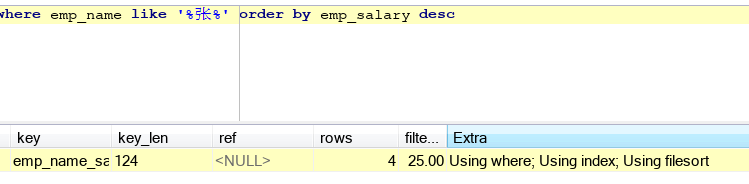
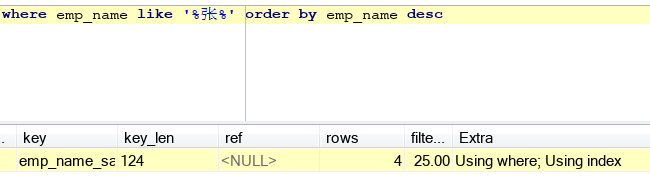
b.order by问题,主要看会不会产生filesort,order by的字段尽量符合最佳左前缀,如下左图,我在员工表里面创建了(emp_name,emp_salary)的组合索引,但我order by没有符合最佳左前缀规则,所以产生了filesort,等下我再改一下order by后面的字段,符合规则vans了,skr。
c.group by,用where就不要用having
3.慢日志
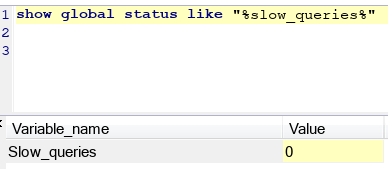
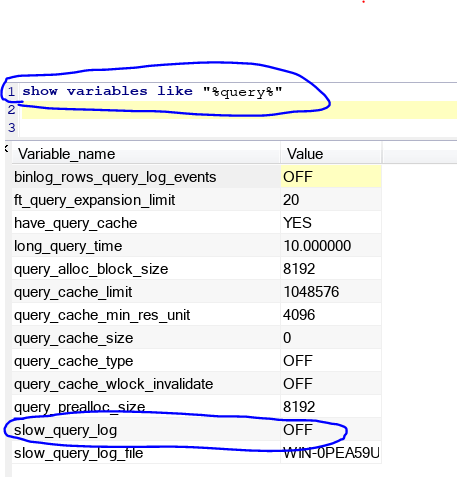
1.其实就是记录查询时间超过阙值(long_query_time)的sql语句。
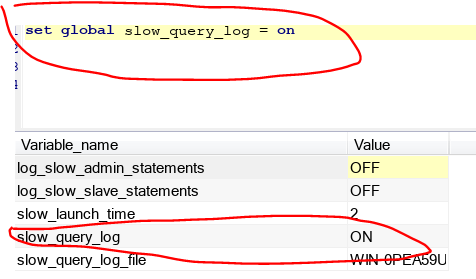
2.怎样开启:set global show_query_log =on,如图下你可以看到目前是关的,我把它set为on就行啦,看右图。
3.查询慢sql:show global status like "%slow_queries%"